해당 포스팅은 엘라스틱 스택 개발부터 운영까지를 읽으며 알아낸 내용을 정리한 글입니다.
현재 프로젝트에 필요한 부분만 우선 선별하여 공부한 내용이니 이 점을 감안하시고 봐주시면 좋겠습니다.
엘라스틱 서치
일단 용어와 개념 익히기 그리고 나서 시스템 만져보기
엘라스틱 서치에서 가장 먼저 익혀야 하는 개념은 데이터 저장, 인출 방식입니다.
인출을 위해서는 데이터를 저장해야하고 저장하기 위해서는 스키마 구성이 필요합니다.
이 과정에서 데이터 타입을 배우고 전문 검색 내부 동작 방식을 이해해야 합니다.
그래야 이 모든 기본적인 것들을 익히고 나서 검색과 집계가 가능해집니다.
저장의 핵심인 인덱스와 document 개념 익히기
Document CRUD, 엘라스틱 서치의 스키마인 매핑 개념 익히기
이런 개념이 현실 즉 서비스 차원에서 어떤 식으로 구체화 되는지 알게되고, 어떤 기능을 사용해야 원하는 결과를 얻게 되는지 감을 잡게 해줄것입니다.
그리고 이런 기초를 탄탄하게 하여 검색과 집계를 잘 다룰 수 있게 될 겁니다!
엘라스틱 서치는 모든 요청과 응답을 REST API 형태로 전달합니다.
REST API는 웹상의 모든 리소스를 URI를 부여하고 HTTP 메서드로 동작을 지정하는 아키텍처입니다.
자세한건 포스팅에서 다루겠습니다.
시스템 상태 확인
Cat API
Cat은 compact and aligned text의 약어로 콘솔에서 시스템 상태를 확인할 때 가독성을 높일 목적으로 만들어진 API 입니다.
curl --location --request GET 'http://localhost:9200/_cat'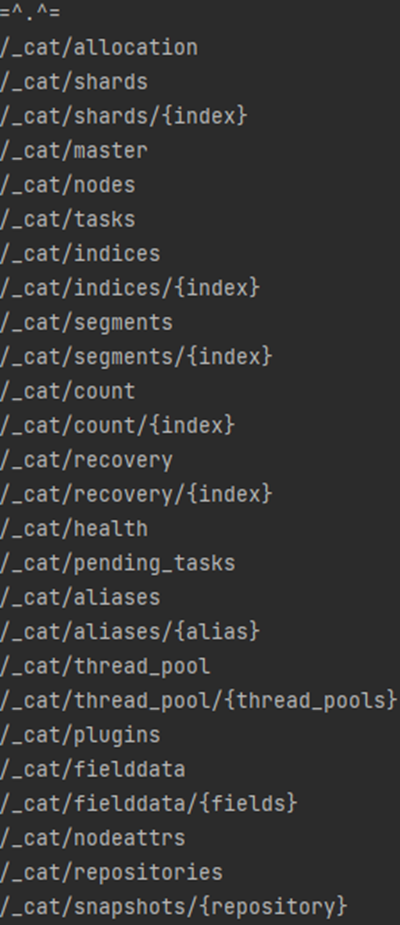
내부 인덱스 목록 확인 요청 명령어는
curl --location --request GET 'http://localhost:9200/_cat/indices?v'지금 Elastic search에 존재하는 인덱스 목록입니다.

저는 filebeat, metricbeat 인덱스가 존재합니다.
? 기호 뒤에 몇 가지 파라미터를 추가할 수 있습니다.
https://www.elastic.co/guide/en/elasticsearch/reference/current/cat.html
Compact and aligned text (CAT) APIs | Elasticsearch Guide [8.8] | Elastic
help is not supported if any optional url parameter is used. For example GET _cat/shards/my-index-000001?help or GET _cat/indices/my-index-*?help results in an error. Use GET _cat/shards?help or GET _cat/indices?help instead.
www.elastic.co
더 자세한건 링크를 타고 cat api 공식문서를 보시면 됩니다.
인덱스와 도큐먼트(document) 개념 익히기
인덱스는 도큐먼트를 저장하는 논리적 구분자이며, 도큐먼트는 실제 데이터를 저장하는 단위입니다.
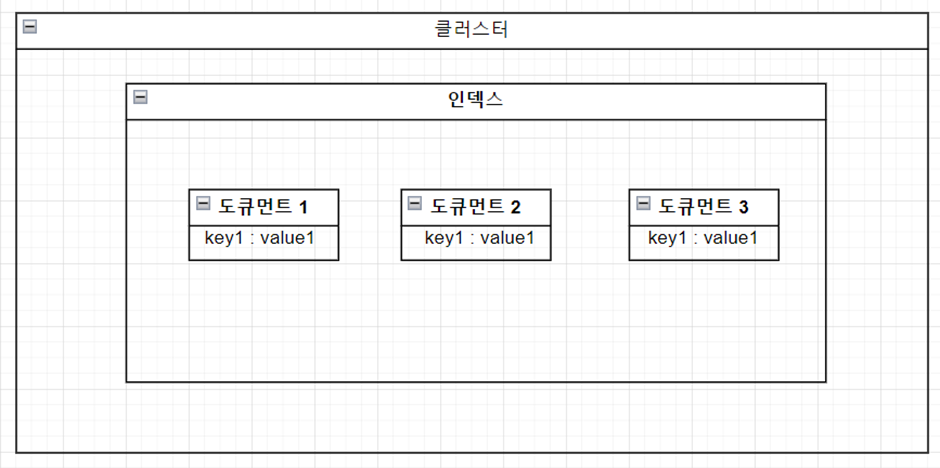
엘라스틱 서치는 클러스터 - 인덱스 - 도큐먼트 – 필드
위의 포함관계를 가집니다.
도큐먼트를 먼저 살펴보겠습니다
엘라스티 서치의 가장 기본적인 데이터 저장 단위는 json 입니다.
하나의 도큐먼트는 여러 필드와 그에 해당되는 값을 갖습니다.
{
“field” : “value”
}
Json은 이런 매핑 정보를 가지고 있고 관계형 데이터베이스와 비교하면
테이블의 스키마 정보를 생각하시면 됩니다.
Ex name,age,gender 컬럼을 가진 Member 테이블
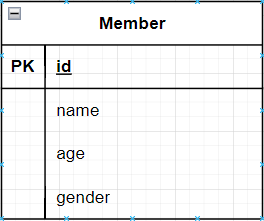
-> Json 형태
{
“name” : “mike”, // field1
“age” : 25, //field2
“gender” : “male” //field3
}
Mysql과 같은 관계형 데이터베이스에 더 익숙한 분들은 해당 비교 표를 통해 엘라스틱 서치를 더 쉽게 이해하실수있으실겁니다.
| Mysql | Elasticsearch |
| 테이블 | 인덱스 |
| 레코드 | 도큐먼트 |
| 컬럼 | 필드 |
| 스키마 | 매핑 |
- 인덱스 개념
인덱스는 관계형 데이터베이스의 테이블과 비슷한 개념으로 도큐먼트들을 묶어주는 논리적인 단위입니다. 동일한 인덱스에 존재하는 도큐먼트는 동일한 스키마를 가집니다.
- 스키마에 따른 그룹핑
일반적으로 인덱스는 스키마에 따라 구분됩니다.
보통 회원 정보 도큐먼트와 장바구니 정보 도큐먼트는 서로 다른 스키마를 저장하고 있으므로 이런 두개의 스키마를 같은 인덱스에 넣고 저장하는 것은 바람직하지 않습니다.
스키마에 따라 인덱스를 구분하자! 는 기본적이며 필수사항 입니다.
- 도큐먼트 CRUD
저는 엘라스틱 서치를 로그 수집 용도로 사용하고 있기 때문에 CRUD의 R 인 읽어오는 동작만 수행합니다. 따라서 GET 을 제외한 나머지 기능들은 넘어가겠습니다.
도큐먼트를 읽어오는 과정은 도큐먼트 id 혹은 DSL 이라는 엘라스틱 서치가 제공하는 쿼리문을 이용하는 방법이 있습니다.
GET index/_search
저는 아래의 명령어를 쳐서 확인해봤습니다.
curl --location --request GET 'http://localhost:9200/.ds-filebeat-8.8.2-2023.07.11-000001/_search'

filebeat가 보내준 데이터라 굉장히 많은 도큐먼트(document)가 존재했습니다.
이 search DLS 을 사용하면 위와 같이 인덱스 내의 모든 도큐먼트를 가져올 수 있고 어떤 매핑 정보들이 있는지는 추후에 포스팅 하겠습니다.
매핑
관계형 데이터베이스에서 테이블 생성시 스키마 생성은 기본이고 중요합니다. 스키마란 테이블 구성요소들의 논리적인 관계를 정의한 것입니다. 스키마를 정확히 설계하지 않는다면 추후 데이터 조회 및 조작에서 문제가 발생할 수 있으므로 아주 중요합니다.
엘라스틱서치에서는 이런 스키마 정의에 해당되는 매핑이라는 개념이 존재합니다.
이런 매핑은 2가지 종류가 존재하는데 엘라스틱서치가 자동으로 매핑해주는 다이내믹 매핑과 사용자가 직접 매핑하는 명시적 매핑이 있습니다.
이번엔 매핑 설정 방법과 어떻게 하면 좋은 매핑이 되고, 매핑할 때는 어떤 타입들이 지원되는지 한번 알아보겠습니다.
다이내믹 매핑
현재 저는 인덱스를 직접 만드는 경우는 없기 때문에 만들지는 않았지만 엘라스틱서치는 사용자가 타입을 직접 지정해주지 않아도 알아서 타입을 예측하여 인덱스를 만들어주는 기능을 제공합니다. 그것이 바로 다이내믹 매핑이고 과정은
진한 부분이 작성자가 지정해줘야 하는 부분입니다.
PUT index명/_doc/1(도큐먼트 고유 ID)
{
"name" : "mike",
"age" : 25,
"gender" : "male"
}
이렇게 하고 요청을 날려주면 엘라스틱서치가 자동으로 도큐먼트 필드들의 타입을 체크하여 매핑을 만들어줍니다.
아래 표는 도큐먼트 원본 데이터의 타입에 따라 어떤 타입으로 자동 매핑되는지 알려주는 표입니다.
| 원본 소스 데이터 타입 | 다이내믹 매핑으로 변환된 데이터 타입 |
| null | 필드를 추가하지 않음 |
| boolean | boolean |
| Float | Float |
| Integer | long |
| Object | Object |
| String | String 데이터 형태에 따라 date, text/keyword 필드 |
//인덱스 확인
curl --location --request GET 'http://localhost:9200/_cat/indices?v'
curl --location --request GET 'http://localhost:9200/인덱스명/_mapping'
ex ) curl --location --request GET 'http://localhost:9200/.ds-filebeat-8.8.2-2023.07.11-000001/_mapping'이렇게 본인이 요청한 인덱스 생성 및 매핑 요청의 결과를 확인해 보실 수 있습니다.
명시적 매핑
사용자가 직접 매핑을 정의하는 것을 명시적 매핑이라고 합니다.
PUT index3
{
“mappings": {
"properties": {
"age": {"type": "short"},
"name": {"type": "text"},
"gender": {"type": "keyword"}
}
}
}
이런식으로 타입을 정확하게 지정해주는 것입니다.
그리고 이런 명시적 매핑을 위해서도 serarch DSL을 이용한 검색 집계 등의 작업을 하기 위해서도 엘라스틱서치에서 제공하는 데이터 타입을 알아두는 것이 좋을거 같습니다.
매핑 타입 ...
이상으로 엘라스틱 서치의 핵심적인 개념인 인덱스/도큐먼트를 알아보았고, 인덱스 정보 조회 및 작성법, 엘라스틱 서치의 스키마인 매핑 개념을 알아보았습니다. 앞으론 엘라스틱서치의 search DSL 쿼리를 사용해서 저의 filebeat,metricbeat 내의 모든 도큐먼트에 접근해서 원하는 정보를 가져오는 방법에 대해서 포스팅 하겠습니다.
'Server' 카테고리의 다른 글
| Spring boot 애플리케이션 ec2에 jar로 배포 (0) | 2023.07.23 |
|---|---|
| aws ec2에서 Nginx + Spring boot Application 연동 (0) | 2023.07.23 |
| filebeat, metricbeat의 module 사용해서 Kibana로 시각화해보기 (2) | 2023.07.16 |
| Nginx 서버에 filebeat와 metricbeat 설치 후 설정파일 작성 (0) | 2023.07.13 |
| Elasticsearch + kibana를 통한 ec2 서버 모니터링 (1) | 2023.07.11 |



